
I often think of classic adventure games as their own thing -- their slow-pace, narrative-oriented nature seem to have more in common with a graphic novel than a video game. Yet some things are ubiquitous, regardless of the genre. For example, real time strategy games, first person shooters, roguelikes, adventure games -- heck, nearly any game, will have some sort of path finding. Today, we're going to look at how I did it in Clojure for Tick's Tales.
The problem: We want to keep our protagonist in a walkable area. As cool and hero-worthy as Tick might be, he still can't walk through walls, buildings, or even grass. Also, we don't want to make Tick look dumb while trying to complete the simple task of walking through a door. If you've ever played any of the SCI0 Sierra games, you might remember infuriating problems like this:
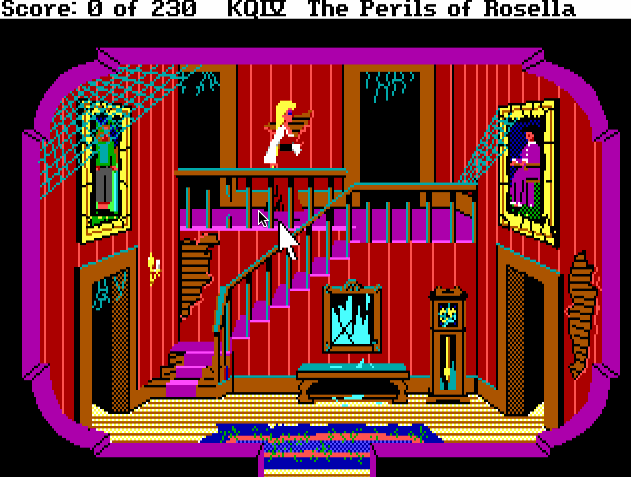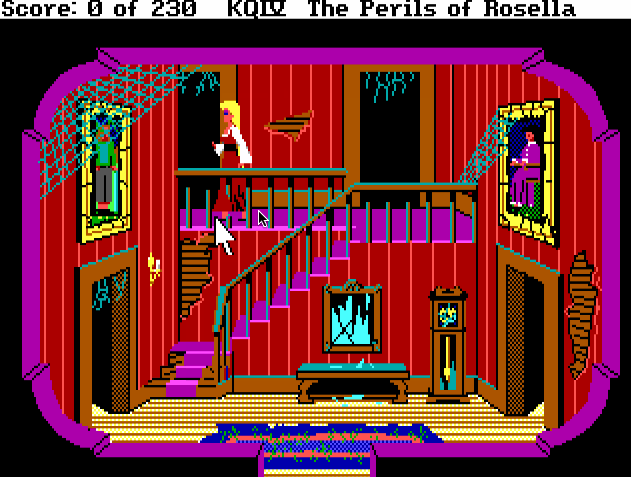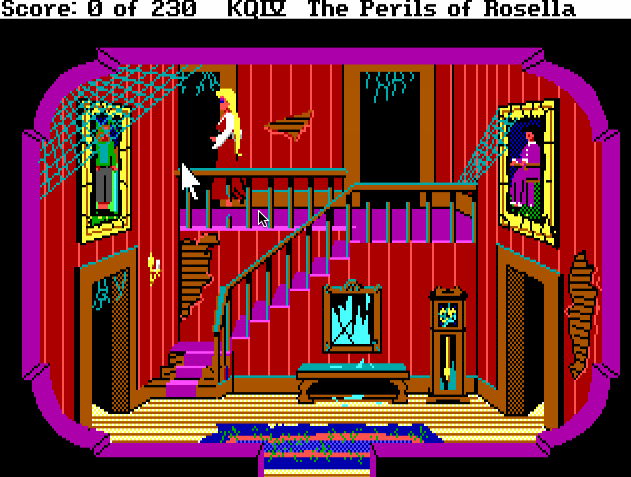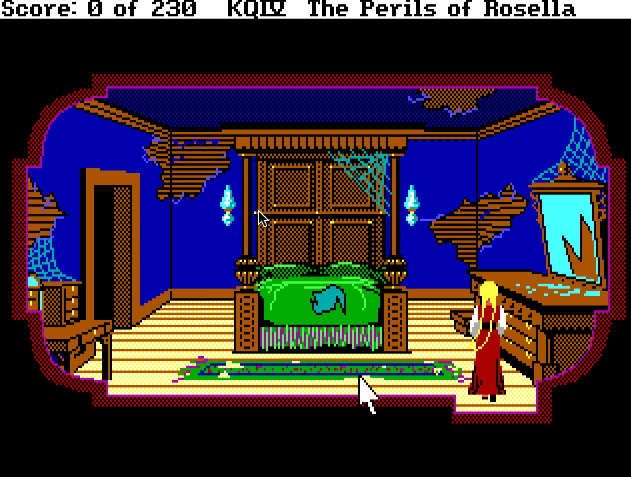
There's a lot of clicking in this gif.
How to get Tick to where I click
There are several approaches to pathfinding. For Tick's Tales, I opted to make a black and white image that would represent the passable and unpassable areas.
We'll load this image as a giant data structure in the game. I scale the image down to half size (160x120). Next, convert each pixel from this image into a vector of vectors, representing what's passable, and what's not.
By way of simple example, let's say that data structure looks like this:
(def c-map [[1 1 1 0 1 1]
[1 1 1 0 1 1]
[1 1 1 0 1 1]
[1 1 1 1 1 1]])
This vector of vectors will serve as a graph for A* pathfinding. There's a wealth of information on this algorithm. If you're unfamiliar with it, or need to brush up on it, I highly recommend you start here.
Now let's say Tick is standing at [0 0], and the user clicked at [0 5] on this map. We can see this visually:

Red represents Tick's starting position, and green represents his destination.
We want to create a function that will take a map like this, the start position, the end position, and returns the path to that position. That is:

In code, it might look something like this.
(defn path-find [collision-map start-pos end-pos] ;; Should return something like this ;; [[0 0] [1 1] [2 2] [3 3] [2 4] [1 5] [0 5]] )
Some nomenclature
Throughout this post, I'll be using a couple of terms that might be useful to know.
- Position: a point on the grid, represented as a tuple of [y x] coordinates. (Yes, that may seem backwards. This done for easy get-in mechanics.)
- Neighbors: All of the adjacent positions to a position.
- Path: A sequence of positions, e.g., [[0 0] [1 1] [2 2]]
- Node: For our purposes, a node will be a tuple of a position and a path. That is, a node represents a position, and the sequence of positions from the start position to that position. For example [[2 2], [[0 0] [1 1]].
- Frontier: A set of nodes to check next
- Visited: A set of positions that we've already visited, to prevent backtracking.
- Heuristic: An approximate distance, used to figure out which nodes are the best candidates of being the right path.
Note: Node might be a departure from what comes to mind if you're already familiar with pathfinding. A* and breath-first-search are graph traversal algorithms, but with our grid-based approach, we aren't really storing our map as a graph with nodes and edges. As such, node is a fitting term for "A position and the breadcrumbs of how we got to that position."
Some precursors
Before we can dive into finding the path between the two points, we'll need to write a function that gives us the neighbors from a given positions.
; each represents adjacent positions, northwest, north, northeast, etc.
(def neighbor-deltas [[-1 -1] [0 -1] [1 -1]
[-1 0] [1 0]
[-1 1] [0 1] [1 1]])
;; get each point that is passable that's adjacent
(defn neighbors [collision-map [y x]]
(let [candidates (map #(mapv + %1 %2)
(repeat [y x])
neighbor-candidates)]
(remove
#(= 0 (get-in collision-map % 0))
candidates)))
(neighbors c-map [2 2])
;; ([1 1] [2 1] [3 1] [1 2] [3 2])
We build up a list of candidates, which is just a sequence of all of the neighbors. Then we filter out any impassable candidates from that list.
Breadth first search
Let's start with the easiest implementation to get Tick to where we want him to go, a breadth first search, which we'll build upon later. It's probably easiest to start visually.

Orange represents the frontier.
In the above animation, we start at the starting position, check its neighbors, then each of its neighbors' neighbors, and so on, until we find the destination. Along the way, we'll keep breadcrumbs of how we got to the current path. Let's take a look at an implementation in Clojure.
(defn breadth-first-path-find [collision-map start-pos end-pos]
(loop [frontier [[start-pos [start-pos]]]
visited (set [start-pos])]
(let [[[current-pos current-path] & frontier] frontier
unvisited-neighbors (->> current-pos
(neighbors collision-map)
(remove visited))]
(cond (nil? current-pos)
[]
(= current-pos end-pos)
(conj current-path current-pos)
:else
(recur (into (vec frontier)
(mapv #(vector % (conj current-path %)) unvisited-neighbors))
(into visited [current-pos]))))))
Let's break it down into the small bits.
(defn breadth-first-path-find [collision-map start-pos end-pos]
(loop [frontier [[start-pos [start-pos]]]
visited (set [start-pos])]
...))
Frontier is a sequence of nodes, each with a position, and the path leading up to that position. In the beginning, we only have one, the start position. But as we recurse through this loop, it'll continually add nodes to the frontier.
We also keep track of visited, containing each of the positions we've already checked. This set is only used to ensure we don't visit the same node twice. Otherwise, we'd end up in an endless loop.
(defn breadth-first-path-find [collision-map start-pos end-pos]
(loop [frontier [[start-pos [start-pos]]]
visited (set [start-pos])]
(let [[[current-pos current-path] & frontier] frontier
unvisited-neighbors (->> current-pos
(neighbors collision-map)
(remove visited))]
...)))
Each iteration of the loop, we're going to check one node to see if we've reached the destination. [current-pos current-path] is a destructured representation of that node. For a few examples of destructuring, see here. One common destructuring form is [[current & more] some-sequence]. It's a shorthand that assigns the first thing in some-sequence to current, and the remaining items more. We leverage that pattern here. We pull off the first node from frontier, and rebind frontier to the remaining nodes. We further destructure the node by getting the current-position, and the current-path.
Now consider again the body of the loop.
(defn breadth-first-path-find [collision-map start-pos end-pos]
(loop [frontier [[start-pos [start-pos]]]
visited (set [start-pos])]
(let [[[current-pos current-path] & frontier] frontier
unvisited-neighbors (->> current-pos
(neighbors collision-map)
(remove visited))]
(cond (nil? current-pos)
[]
(= current-pos end-pos)
(conj current-path current-pos)
:else
(recur (into (vec frontier)
(mapv #(vector % (conj current-path %)) unvisited-neighbors))
(into visited [current-pos]))))))
Each loop, we check to see if the current node is nil. This happens when we have hit every possible position there is, and still haven't found the end-pos. In this situation, there is no path to destination, so we return an empty path.
If we find the end-pos, we add it as our last step in the path, and we're done.
Otherwise, we continue looping, adding all unvisited neighbors to the frontier. When we do, we add the current position to the path. We also add the current position to the visited set, to ensure we don't backtrack and get stuck in an endless loop.
All done... or are we?
Breadth-first search is just too slow. Even in our very simple example, every single position is checked. But in Tick's Tales, the map is 160x120, or 19,200 positions to check, each with breadcrumbs detailing how it got there. Since we short circuit if we find the end position, we won't always check all 19,200, but that's still going to be crazy slow.
Let's take a look at another example on the same map, and hopefully it'll illustrate how we can improve our solution.

Tick starts looking to the left, and to the right. Shouldn't he check out the right first? We'll use A* to do just that.
A* search
There's really only one difference between the breadth first search and the A* search. An A* search tries to find the best neighbors to search first, rather than searching all directions equally.

Which are the best neighbors? The best neighbors are a combination of two things:
- Proximity to the destination. This may seem self explanatory; we check the nodes that are closest to the destination first.
- The distance traveled so far. This might seem less intuitive. The basic idea is that just going in the path of the destination might lead to a dead end. If it does, Tick would walk into the wall then start walking the perimeter until he finds a way around it. He'll still make it to the destination, but it won't be a very direct path. By factoring in the total distance traveled, we consider other options, trying to go around the obstacle in the first place.
(defn heuristic [[x1 y1] [x2 y2]]
;; approximate the distance to the destination, using manhattan distance.
(+ (Math/abs (- x2 x1))
(Math/abs (- y2 y1))))
(defn a*-path-find [collision-map start-pos end-pos]
(loop [frontier (p/priority-map [start-pos []] 0)
visited (set [start-pos])]
(let [[[current-pos current-path] c] (peek frontier)
frontier (pop frontier)
unvisited-neighbors (->> current-pos
(neighbors collision-map)
(remove visited))]
(cond (nil? current-pos)
[]
(= current-pos end-pos)
(conj current-path current-pos)
:else
(recur
(reduce (ƒ [frontier neighbor]
(let [neighbor-path (conj current-path current-pos)]
(assoc frontier [neighbor neighbor-path]
(+ (count neighbor-path)
(heuristic neighbor end-pos)))))
frontier
unvisited-neighbors)
(into visited [current-pos]))))))
I've highlighted the differences from the breadth-first search.
- We added a heuristic function. This is used to give an approximate distance the destination, using manhattan distance. If we weight based off this value, Tick will avoid going to the left in the example above.
- Our frontier vector has been replaced with a priority-map, which is part map, part list. Instead of conjing on to it, we assoc. This allows us to specify the node, and the priority of the node. When reading from the priority-map (using peek and pop), it will be sorted by the priority. Here's a little example of how this works:
(peek (assoc (p/priority-map) :a 500 :b 1 :c 501)) ;; [:b 1] ;; Notice b comes first, because keys are popped of in order of the value.
- Jump down to the reduce, the meat of what's changed. Instead of just adding all of the unvisited neighbors to the end of the frontier, we have to assoc each one, specifying its priority. We use reduce to do this. To prioritize, we include both the distance traveled so far (the number of steps in the path) and the heuristic (approximate distance).
There you have it! We can test our pathfinding now:
(a*-path-find c-map [0 0] [0 5]) ;;[[0 0] [1 1] [2 1] [3 2] [4 3] [3 4] [2 5] [1 5] [0 5]]
Lessons Learned
Even though this solution is relatively simple (heck, it's barely 30 lines of code!), there is a lot I'll do differently next time around. It's difficult to get into all the nitty-gritty in a blog post, but I'll share a little bit of what I learned along the way.
- The code in this post resembles what I started out with for Tick's Tales, but not what I ended up with. I quickly found that any implementation using immutable datastructures and a pixel-perfect grid based approach (like above) is still too slow. In the end, I reverted to using java.util.PriorityQueue in the end.
- The paths sometimes come out really jerky. I had to implement some smoothing after calculating the path.
My conclusion from this is that a grid-based approach is great for real time strategy games, but I'd probably switch to a graph based on polygons (like navmesh) if I started over. The advantages of this are threefold:
- The total number of nodes would be drastically smaller from the 160x120 maps shown here. It'd go from 19,200 to around 50 or so in most cases.
- The paths would automatically be smooth, because the steps in the paths would be straight lines from point to point.
- As a result of the small graph size, I'd be able to keep an immutable solution.
That's all for now. Hopefully this was helpful!